|
||
|
|
||||||||||||||||||||||||||||||||||||
|
|
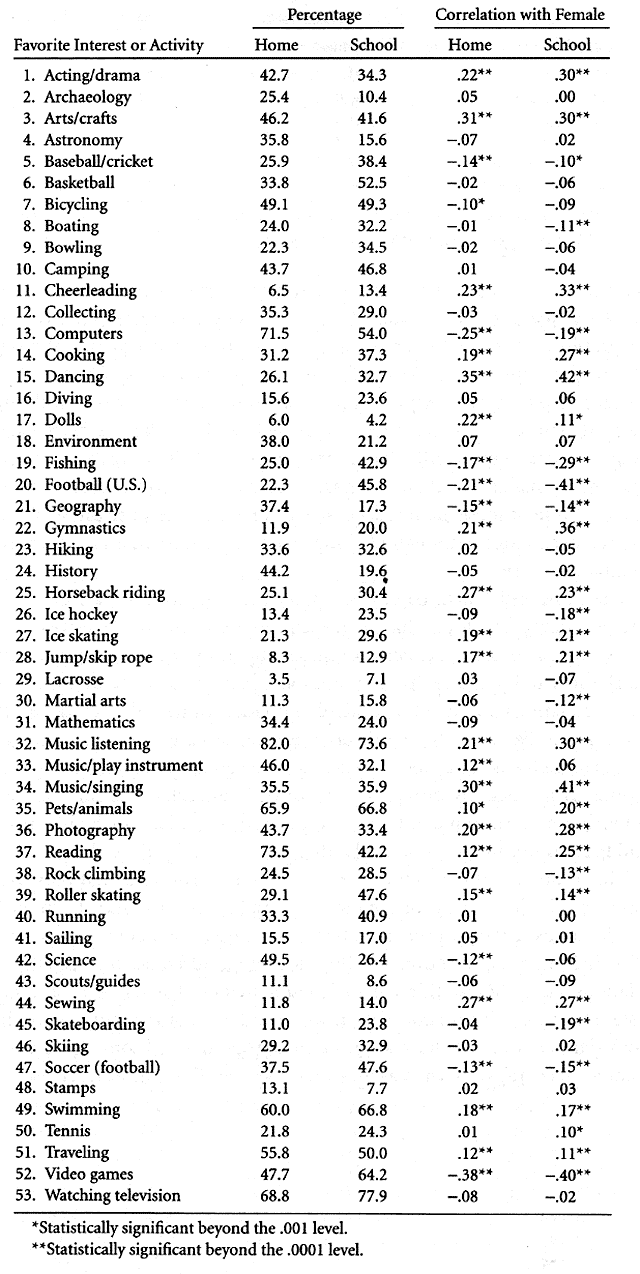
The World Wide Web offers many advantages for administering questionnaire surveys, yet survey researchers are reluctant to use it because of concerns about the quality of respondent samples. 1 This chapter considers the value of Web-based surveys and questions that must be addressed about their reliability and validity, anchoring the discussion in data from 2,382 children aged thirteen through fifteen obtained in late 1998 as part of the Survey 2000 project. 2 Our analytical method is to compare responses from two very different subsets of respondents. To illustrate the substantive value of Web-based survey data, we focus on an empirical question of widespread scientific and public interest: the differences in attitudes and interests between girls and boys. In addition, the design of this study reveals much about the differences between children who actively use the Web and those who do not. On November 2, 1999, The Washington Post reported that women slightly outnumber men among AOL subscribers and that they are approaching parity among American users of the Internet more generally. 3 It seems likely that AOL's subscriber list is unrepresentative, but a number of different indicators seem to show that women are increasing their representation in a number of previously male domains. For example, from 1966 to 1995, the proportion of American doctorates in science and engineering going to women rose from 8.0 percent to 31.2 percent. 4 A survey of a narrow age group done at a single point in time cannot chart changes over the years. But it can examine the connections between gender and a number of other variables, explore the connections between those variables, and identify indicators and measurement scales that can be used in a series of studies over time to see how the transformations are progressing. Our goals here are primarily methodological, but we use the issue of gender differences to illustrate the problems and advantages of Web-based questionnaires. Survey 2000 was an extensive, pioneering Internet survey sponsored by the National Geographic Society and created by a team headed by sociologist James Witte. There were several versions of the survey for people of different ages and nationalities. About 50,000 adults completed the survey, mostly Americans and Canadians but with at least 100 from each of thirty-three other nations. The chief focus of the survey was migration, regional culture, and community involvement. For U.S. and Canadian respondents over age fifteen, the computer individually tailored sections of the questionnaire about food and literature preferences in accordance with the respondent's region of birth and current region of residence. Some of the numerous questions about musical preferences played sound clips over the respondent's computer, asking him or her to evaluate them. Children aged thirteen through fifteen answered a long but straightforward questionnaire containing major sections of questions about their favorite activities, musical preferences, friends' values, and attitudes toward science. A total of 2,942 completed the survey at one of five locations: at home (51.3 percent), at school (40.6 percent), at a parent's workplace (1.7 percent), at a community center or library (1.3 percent), or at some other location such as a friend's house (3.3 percent). Most of those who responded at school did so as part of a class assignment in connection with Geography Awareness Week, and National Geographic recruited teachers in all U.S. states and Canadian provinces to have their students participate. Thus, school respondents are more like a random sample than are the teenagers who responded at home, attracted by advertisements in National Geographic publications and on the society's popular Web site. 5 Concerns about Web-Based SurveysSociology, political science, cultural anthropology, and perhaps several related fields are not merely sciences but also include aspects of the humanities, social criticism, and political action. In addition, their topic areas are highly complex, and even the best scientific methods have limited power. Thus, there is a constant danger that other tendencies will overwhelm the scientific orientation of these fields, and researchers dedicated to systematic methods are understandably nervous about relaxing their standards of rigor. Ultimately, they may fear that the dam of rationality may burst, and antiscientific elements will take over these vulnerable fields. In this context, Web-based surveys may seem dangerous, even reckless. This is not the place to critique traditional survey methods or to criticize particular existing surveys. But it should be noted that expensive national samples fall somewhat short of being true random samples, and the complexity of their sampling frames often makes it difficult to determine the exact degree to which this is the case. Furthermore, the high cost of this approach typically limits the number of items that can be included. Much of the sophisticated multiple-indicator methodology developed a quarter century ago has been abandoned in a heroic attempt to maximize the representativeness of the sample. Some political scientists give a high priority to predicting election outcomes, and for them the sample of respondents should match actual voters as closely as possible. 6 Research that attempts to track social indicators over time, such as the structure of the American family or the personal well-being of citizens, needs stable sampling methods throughout the years. Studies of social class stratification certainly need data about all social classes, and random samples may be the best way to obtain them. On the other hand, other research areas such as culture, ideology, personality, and economic preferences may need data about a very large number of variables, some of which may be meaningful only to small subgroups in the general population. Some of my own work falls in this area, notably studies I did using informal purposive samples of people who had thoughts and opinions about space flight and science fiction, topics of little interest to most citizens. In each case, a battery of more than 100 questionnaire items were to be rated on a consistent scale, and the data were subjected to an exploratory factor analysis or cluster analysis to identify dimensions of variation or groups of items that fit together in respondents' minds. The aim is to identify underlying cultural schemas, folk categorization systems, or other mental constructs that guide people with respect to the topic in question. As in the development of personality tests in psychology, nonrandom samples produced the initial data for identifying clusters of cultural elements and developing measurement scales. Subsequent research can determine whether the findings generalize to other populations. The reliability and validity of Web-based surveys are a subject for research and debate, not assumption, and may depend very much on the scientific goals. Surveys can be targeted to specific populations and even to selected lists of individuals over Internet and need not be a convenience sample of visitors to a Web site. 7 However, the difficulty of motivating targeted individuals and the fact that many people still cannot be reached via Internet mean that Web-based surveys may often be far less representative than conventional surveys, even though the latter fall short of being true random samples of the population. Thus we need to develop means to compensate for these limitations, to the extent possible, which requires us to explore the nature of these limitations empirically. Young teens who responded at home to Survey 2000 probably differ from at-school respondents in several ways. There ought to be social class differences because computers with Internet access are still much more common in affluent households. Most at-home respondents found the survey from advertisements in the National Geographic Society's magazines or Web site, so they are probably more intellectual and culturally cosmopolitan than the average child their age. On the other hand, they are probably less busy with other things that would prevent them from surfing the Web, such as social gatherings and outdoor activities. The following analysis examines gender differences in four groups of Survey 2000 items: favorite activities, attitudes toward science, musical preferences, and peer values. For each group of items, we compare the two groups of respondents in terms of the proportions who respond in a particular way and in the correlations linking the items to being female. We are particularly interested in cases in which one group exhibits a significant correlation but the other does not. All items in this study are dichotomous, and items that were recoded were handled in such a way that there are no missing data. This allows us to use simple quantitative methods of analysis, but the data will be made available by National Geographic to interested scholars who want to try different or more complex statistical techniques. Favorite ActivitiesThe largest section of the youth survey was headed "What Do You Like?" Three pages containing fifty-three items were offered with these instructions: "Look through the following list of activities and interests. Which are your favorites? (Check as many as apply.)." For example, the first page had six rows of three items each, and the first row was "q Acting/drama q Archaeology q Arts/crafts." The box to the left of each item was an HTML checkbox that allows the respondent to select as many of the items as desired. The first two columns of table 3.1 report how many children in each of the two groups checked each of the fifty-three boxes. For example, 42.7 percent of the children who answered at home checked the box for "acting/drama," compared with 34.3 percent of those who responded at school.
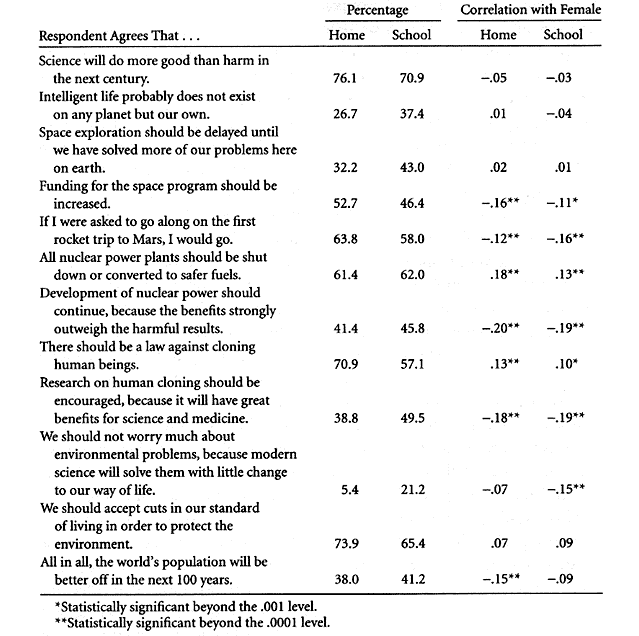
The fifty-three items are listed in alphabetical order, but it may make more sense to consider them in groups, based on how children responded to them. For example, there were twenty items for which there was a difference of more than ten percentage points in the proportions of the two groups who say the activity is one of their favorites. The at-home respondents were markedly more enthusiastic about archaeology, astronomy, computers, environment, geography, history, mathematics, music (playing an instrument), photography, reading, and science. Most of these distinguish readers of National Geographic Magazine who enjoy using a computer, qualities that would have motivated the child to take the survey in the first place. The at-school respondents showed significantly more interest in baseball, basketball, bowling, fishing, football, ice hockey, roller skating, skateboarding, soccer, and video games. None of these are intellectual activities, most require physical activity, and even video games and fishing generally require manual rather than mental dexterity. The third and fourth columns in table 3.1 give the correlations (tau-b) between being female and having the activity for a favorite. Positive correlations, such as those for cheerleading, sewing, music/singing, and cooking, mark the activity as one that girls are more likely to favor than boys. Negative correlations, notably for football and video games, identify things that boys tend to like more than girls do. It is interesting to note that among today's young teens, a number of activities are equally popular, having correlations insignificantly different from zero. A few activities, such as stamp collecting, are so unpopular that the response distributions are highly skewed, and there is not much room in the data for boys and girls to differ. The important thing to note for our present purposes is that most items have very similar correlations in the two samples, at-home and at-school. We would not expect the numbers to be identical because there is random variation in both sets of respondents. But the average difference between the correlations is only .06. For thirty-five of these activities, at least one dataset shows a statistically significant correlation with gender, and for twenty-six of these both datasets do. But there are nine instances in which one dataset has a significant correlation whereas the other does not. These deserve a close look. In five of the nine cases (bicycling, playing a musical instrument, martial arts, rock climbing, and science), the two coefficients differ by no more than .06, which is the average difference across all fifty-three pairs. In the case of bicycling, the correlation at home is –.10, and at school it is –.09, a difference of just .01. Clearly the correlation at home is barely above the threshold of statistical significance, and the correlation at school is slightly below it. Even if both sets of respondents were perfect random samples of the population, one would expect many differences of this insignificant size. To assess the statistical significance of differences between the correlations, I wrote a bootstrapping computer program that worked as follows. It took the data, divided into two comparison groups of 1,191 who responded at home or at school, and recalculated the correlations for a selected activity. Call these correlations A (home respondents) and B (school respondents). At each step of the simulation it derived a random sample of 1,191 from each group of respondents, with replacement. That means that some respondents might be represented several times in the sample and others not at all, but the simulated samples would have characteristics similar to those of the original data. Finally, it calculated new correlations, A' and B', and compared them. For each significance test, the program iterated this calculation-intensive procedure 1,000,000 times. From these simulation trials, the program derived the probable distribution of correlations from samples. If the correlations in the data are such that A < B, then the statistical significance of the difference in correlations is the fraction of the simulation iterations in which B' ³ A'. These tests show that the differences for five of these variables are not statistically significant: bicycling (probability estimated to be .34), playing a musical instrument (.09), martial arts (.1), rock climbing (.09), and science (.07). Three others are moderately significant: boating (.005), tennis (.02), and ice hockey (.01). The statistical significance of the .15 difference for skateboarding (–.04 at home and –.19 at school) is highly significant (.00003). It is worth noting that the response distribution concerning skateboarding is highly skewed for the at-home respondents. Only 12.1 percent of boys responding at home claim to engage in skateboarding, compared with 10.1 percent of girls. The bootstrapping method of assessing statistical significance takes care of the statistical difficulties involved with highly skewed data and is a robust estimator technique based on the actual distributions of values for the variables rather than on some abstraction such as the statistical normal curve, but it does not deal with a more fundamental measurement issue aggravated when the distribution is skewed. An unknown fraction of the respondents are claiming to skateboard when they may have tried the sport only once or twice or merely mean that they might want to try it in the future. In other words, there is always some level of meaningless noise in the data, and when a distribution is highly skewed the noise may dominate the correlations. Thus it could be that the insignificant negative correlation between skateboarding and being female among the students responding at home results from the fact that none of these Web-surfing readers of National Geographic actually skateboard—or perhaps only 2 percent of the boys—and something like 10 percent of the respondents are emitting noise that is uncorrelated with sex. Another highly skewed example is cheerleading, which has a correlation with being female of .23 among the at-home respondents and .33 among the at-school respondents. The difference between the gender and cheerleading patterns in the two samples is highly significant (.0002). But this may merely reflect the fact that hardly any of the at-home respondents claim to do cheerleading, 6.5 percent at home compared with 13.4 percent at school. Even when the distribution of one variable is highly skewed, given a large number of cases a real relationship may be detectable despite the noise. Attitudes toward ScienceThe early-teen version of Survey 2000 included several agree-or-disagree items specifically to advance my research on attitudes toward science and technology, and they are listed in table 3.2. Four response categories were offered: "strongly agree," "agree," "disagree," and "strongly disagree." The online survey used a radio button method for responding that prevented a respondent from selecting more than one response but did permit no response. About 1 to 4 percent of the respondents failed to answer a given question in this group of twelve. For purposes of this study, I dichotomized the variables, coding "1" for agree and strongly agree and "0" for disagreement and nonresponses. This is substantively meaningful because it clearly distinguishes those who expressed agreement with each statement from those who did not. By dichotomizing responses to these twelve items, I made them comparable to the fifty-three items in table 3.1, allowing us to use a uniform approach. Naturally, other studies will use the data in their original form. We might expect the at-home respondents to differ significantly from those who responded at school in their levels of agreement with the science and technology items, chiefly because they are probably National Geographic readers and this magazine sensitizes readers to several scientific issues, notably those concerning the environment. In addition, it is possible that habitual Web surfers have a different and possibly more favorable orientation toward technology because they are willing computer users. Some social scientists might argue that one virtue of a random sample is that it will reflect greater variation on most variables, whereas a convenience sample is likely to exhibit truncation on several variables and thus be inferior at detecting relationships and measuring them accurately. This may well be the case for many of the activities listed in table 3.1. However, the opposite could be argued for many of the science and technology attitudes listed in table 3.2. Perhaps these issues have been rendered more salient for at-home respondents by the fact that they read National Geographic and similar publications. Indeed, one of the traditional critiques of survey research has been that many respondents may not have meaningful responses to many questions. 8
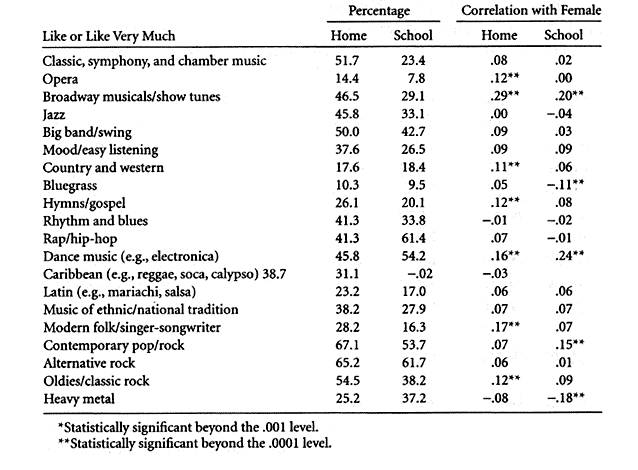
The data cannot entirely resolve this issue, but they do illuminate it. The average percentage who agree across the twelve items is quite similar in the two groups of respondents: 48.4 percent at home and 49.8 percent at school. But the proportions range more widely across items at home. The average difference from the mean is 18.0 percentage points at home, compared with only 10.7 percentage points at school. The average absolute value of the correlations is .11 both at home and at school (or .117 and .108, respectively). And the correlations range only slightly more widely at home, an average of .06 versus .05. We can interpret this pattern as follows. At-home respondents read more than do at-school respondents, on average, and they are much more likely to be National Geographic readers. Thus many of the science and technology issues are more salient to them, and they have better-informed opinions. Because of the particular items chosen, especially the fact that the list contains both protechnology and antitechnology items, this fact does not greatly affect the average level of agreement across the twelve items. However, it does produce a wider range of responses. There is little net impact on the correlations between these items on gender because the effect of gender is not mediated by a deep intellectual understanding of the issues. The intellectual issues may be far more salient for the at-home respondents, and they may provide superior data for many scientific purposes. This last observation is supported by an examination of the correlations linking logically related attitudinal items. Eight of the twelve statements were written in pairs, one member of each pair being favorable to a particular aspect of science and technology and the other unfavorable. Consider this pair of statements: "Space exploration should be delayed until we have solved more of our problems here on earth" and "Funding for the space program should be increased." Although these items are not exact mirror images of each other, a person who agreed with the first might be expected to disagree with the second. Indeed, the correlation between them in the at-home group of respondents is –.33. But among the at-school group the negative relationship is much weaker, only –.14. This very large difference supports the hypothesis that the science and technology items are more salient to the at-home group and receive more thoughtful responses from them. The three other pairs show the same effect. Among at-home respondents, there is a very strong correlation of –.52 between "All nuclear power plants should be shut down or converted to safer fuels" and "Development of nuclear power should continue, because the benefits strongly outweigh the harmful results." But the negative association is only –.18 in the at-school group. Similarly, at home there is a correlation of –.51 between "There should be a law against cloning human beings" and "Research on human cloning should be encouraged, because it will have great benefits for science and medicine." Again, the correlation is weaker at school, –.31. Finally, among at-home respondents there is only a very small but statistically significant correlation of –.16 between "We should not worry much about environmental problems, because modern science will solve them with little change to our way of life" and "We should accept cuts in our standard of living in order to protect the environment." At school, this relationship actually goes the other side of zero, +.06, statistically significant at the .05 level. Perhaps the at-school respondents merely responded to the word "environment" in both statements, treating them as similar instead of opposite, possibly not even appreciating fully what the sentences meant. Musical PreferencesThe chief focus of the adult survey was popular culture, and twenty items about musical preferences were carried over into the youth survey. These items were preceded by the instruction, "Please indicate your feelings about each type of music." The response categories were "like it very much," "like it," "have mixed feelings about it," "dislike it," "dislike it very much," and "don't know much about it." For purposes of this chapter I dichotomized response data, distinguishing respondents who said they liked the particular kind of music from all other respondents. Table 3.3 lists the twenty kinds of music.
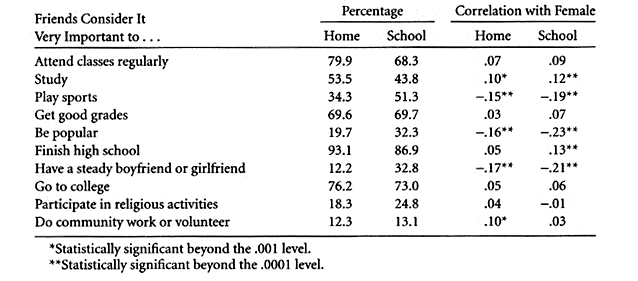
Interestingly, there are very clear and powerful differences in musical tastes between the at-home and at-school respondents. I speculate that they reflect social class differences because presumably at-home respondents live in much more affluent homes that already had Internet connections in late 1998, but I do not have the data to test that hypothesis. 9 Only four musical styles are liked more often by the at-school respondents: country and western; rap or hip-hop, dance music, and heavy metal. On average, 42.8 percent of at-school respondents like these four types of music, compared with 32.5 percent of at-home respondents. In contrast, on average just 29.5 percent of at-school respondents like the other sixteen types, compared with 39.9 percent of at-home respondents. In table 3.1 we see that at-school respondents have a slightly greater tendency to like dancing, 32.7 percent compared with 26.1 percent, and about the same tendency to like singing, 35.9 percent versus 35.5. But the proportion of at-school respondents who played an instrument was much lower, 31.1 percent versus 46.0, although respondents' definition of what it meant to play an instrument must have been liberal. There is even a difference on listening to music, with 73.6 percent of at-school respondents marking this as a favorite activity compared with 82.0 percent of at-home respondents. Again, the two groups of respondents have similar patterns of correlations between musical tastes and gender, with a few notable exceptions. The statistically significant difference on opera, .12 at home versus .00 at school, is easy to explain in terms of the extremely skewed distributions, notably the fact that only 7.8 percent of at-school respondents claim to like this specialized and costly art form. The significant difference on bluegrass, –.11 at school and +.05 at home also involves a highly skewed variable, but the distributions are about the same in the two groups, so an explanation would have to be somewhat subtle. Other correlation differences are minor but occasionally statistically significant. Peer ValuesThe final group of items we will consider offered respondents a list of things such as "attend classes regularly" and "be popular," asking, "Among the friends you hang out with, how important is it to...." Three radio button responses were offered: "not important," "somewhat important," and "very important." I dichotomized the data to contrast "very important" with all other categories (including no response), because this produced the most balanced distribution across the ten items, which are listed in table 3.4.
Several of the peer values concern school, and these show an interesting pattern of differences between the two groups of respondents. Essentially identical percentages of both groups say their friends consider getting good grades to be important. Overwhelming majorities of both groups consider finishing high school to be important, but even a bigger majority of those answering at home, 93.1 percent versus 86.9. The difference on going to college is small, just 3 percentage points in favor of the at-home respondents. These three items all concern goals, but the two items about means to these goals show larger differences, around 10 percentage points. More of the at-home respondents say their friends value attending classes regularly and studying. At-school respondents are much more likely to say that their friends value three items having to do with peer-group social activities: playing sports, being popular, and having a boyfriend or girlfriend. Those who responded at school are also slightly more likely to report that their friends value religious activities, which may again reflect a social class difference. The pattern of correlations is similar across the two groups, and the exceptions are two highly skewed variables. With 93.1 percent of the at-home respondents saying finishing high school is a peer value, there really is not much room for a correlation connecting this variable with gender. The statistical significance of the difference between the tau correlations in the two groups of respondents is .03, figured by the bootstrap method. The item about doing community or volunteer work is also highly skewed, but about equally so in both groups of respondents, and the difference in the correlations is only .07. ConclusionOur discussion highlights the differences between the at-home and at-school respondents, but in many respects the responses of the two groups are very similar. The tables compared percentages and correlations for 95 variables, a number large enough to consider using statistical analysis to compare the two subsamples. At home, the average proportion giving the "yes" or "agree" response was 37.4 percent, compared with 36.8 percent at school. The average correlation at home was .03, compared with .02. Because the correlations are a mixture of positive and negative values, a better measure of the strengths of the relationships is the absolute value of correlations, ignoring the minus signs. The average absolute value of correlations is .11 at home and .13 at school. The correlation (Pearson's r) between the 95 percentages at home versus in school is .83. This is a strong association, but the correlation between the correlations in the two groups is higher, .92, very close to unity. All these analyses indicate that the pattern of results is similar across the two different groups, especially the correlations. The at-school group is more like a random sample than the at-home group, but of course it is far from a random sample of American and Canadian schoolchildren. But we must keep in mind that random samples are only one of several methods for rendering results generalizable. An alternative method is experimentation, with random assignment of research subjects to treatment and control groups. Survey 2000 demonstrated the techniques needed for online experimentation because it administered different questions to different adult respondents, but it did not do so following a theory-based random manipulation plan. One approach that could easily incorporate the experimental method into online surveys is the vignette method. The respondent is given a little story to read and then is asked a number of questions about the people or events described therein. The experimental manipulation is that the contents of the story are altered at random for different respondents (for example, independently varying the race, age, and sex of a character in the story to see whether people judge him or her differently). We have just carried out a nonexperimental form of analysis that can compensate for many of the defects of nonrandom samples. This is repeated replication of the same study with different groups believed to differ significantly in terms of relevant parameters. Because our at-home and at-school groups differed greatly on a number of important variables, any finding that is fundamentally the same in both datasets is of interest. Future major online surveys could target a number of very different groups and use sophisticated variants of meta-analysis to determine how the phenomenon of interest varies across the population. 10 It is very important to note that multiple replication on different groups within a single study not only gives greater confidence to the more consistent results but also can help us understand what makes some measures and correlations vary across different social contexts. If we know what sample selection factors affect the variables of interest in a particular research study, we can compensate to some extent with statistical weighting procedures. Especially in the adult versions, Survey 2000 was designed to include variables that would permit such weighting, and future studies will report the results. Of course, if inexpensive Web-based surveys produce a really interesting finding with some regularity, then a good argument can be made for including the best measures in an expensive survey carried out by more traditional means. The present study finds that Web-based volunteer survey samples may indeed diverge significantly from the data that would have been obtained from a pure random sample, but it is possible to identify and to some extent protect against their biases. For example, we have seen that it is risky to rely on variables with highly skewed distributions and correlations that are only marginally significant. General patterns of correlation may be more robust than the frequency distribution of a single variable. By using two or more distinctly different samples, one can judge the generalizability of findings. Were this a substantive study of gender differences among children rather than a methodological exploration, we would have examined some of the empirical findings of this study closely. The differences between the genders with respect to interest in mathematics and several of the sciences are very small or nonexistent, although girls have less favorable attitudes toward space flight, nuclear power, and human cloning. Given all the public interest in gender fairness in school sports, it is interesting to see that in both groups of children, of the athletic activities preferred by girls only gymnastics is widely offered at schools, basketball is gender-neutral in popularity, and schools that want to support healthy physical activity for girls might want to consider adding dancing to the competitive team sports preferred by boys. Recognizing that the two groups of respondents differ in National Geographic readership as well as Web usage, those responding at home seem far more intellectual and far less active socially. If these particular findings seem unsurprising, then at least they reinforce our confidence that Web-based surveys are capable of achieving valid results. Notes1. Colleen M. Kehoe and James E. Pitkow, "Surveying the Territory: GVU's Five WWW User Surveys," The World Wide Web Journal 1: 3 (1996): 77-84, available at <http://www.cc.gatech.edu/gvu/user_surveys/papers/w3j.html>; Christine B. Smith, "Casting the Net: Surveying an Internet Population," Journal of Computer-Mediated Communication 3: 1 (1997), available at <http://www.ascusc.org/jcmc/vol3/issue1/smith.html>. 2. James C. Witte, Lisa M. Amoroso, and Philip E. N. Howard, "Method and Representation in Internet-Based Survey Tools: Mobility, Community, and Cultural Identity in Survey 2000," Social Science Computer Review 18 (2000): 179-95. 3. S. Stoughton and L. Walker, "Shopping for Presence Online," Washington Post (online edition), November 2, 1999 (p. A1 in the print version). 4. National Science Foundation, Women, Minorities, and Persons with Disabilities in Science and Engineering: 1998 (Arlington, Va.: National Science Foundation, 1999), 255. 5. National Geographic Society Web site at <http://www.nationalgeographic.com>. 6. James E. Campbell and James C. Garand, Before the Vote: Forecasting American National Elections (Thousand Oaks, Calif.: Sage, 2000). 7. David Schaefer and Don A. Dillman, "Development of a Standard E-mail Methodology," Public Opinion Quarterly 62 (1998): 378-97. 8. Howard Schuman and Stanley Presser, "Public Opinion and Public Ignorance: The Fine Line between Attitudes and Nonattitudes," American Journal of Sociology 85 (1980): 1214-25. 9. Department of Commerce, Falling through the Net: Defining the Digital Divide (Washington, D.C.: Department of Commerce, 2000) available at <http://www.ntia.doc.gov/ntiahome/fttn99/contents.html>. 10. B. T. Johnson, "Insights about Attitudes: Meta-Analytic Perspectives," Personality and Social Psychology Bulletin 17 (1991): 289-99. |
||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
|
|
|
||||||||||||||||||||||||||||||||||
| The content of this electronic work is intended for personal, noncommercial use only. You may not reproduce, publish, distribute, transmit, participate in the transfer or sale of, modify, create derivative works from, display, or in any way exploit this electronic work in whole or in part without the written permission of the Board of Trustees of the University of Illinois. | ||||||||||||||||||||||||||||||||||||
|
All rights reserved |
||||||||||||||||||||||||||||||||||||